Резюме: эта статья поможет вам разобраться в том, как использовать оператор SQL SELECT DISTINCT для удаления дубликатов из результирующего набора данных.
Введение в оператор SQL DISTINCT
Скрыть дублирующие строки из выборки, вы можете благодаря предложению DISTINCT в команде SELECT, перед блоком FROM. Пример применения:

Если вы указываете одну колонку после выражения DISTINCT, то именно значения в этой колонке при выборке SELECT применяется для оценки дублей.
При перечислении двух или более столбцов, оператор SELECT DISTINCT станет использовать комбинацию значений в этих колонках для оценки дубликатов.
Следует обратить внимание на то, что оператор DISTINCT удаляет только дубли строчек из набора результатов SELECT. По сути он скрывает дублирующие значения в выборке, но не удаляет физически дубли строк из таблицы.
Вместо DISTINCT стоит применять предложение GROUP BY в команде SELECT если необходимо выбрать два столбца и скрыть дубли в одном столбце.
Примеры SQL DISTINCT
Чтобы продемонстрировать работу оператора SELECT DISTINCT в SQL возьмем для примера таблицу employees.

1) Пример использования оператора SQL DISTINCT на одном столбце
Команда SELECT FROM ниже отберет данные по зарплате из колонки «Зарплата» таблицы «Сотрудники» и отсортирует строки их от максимума к минимуму:

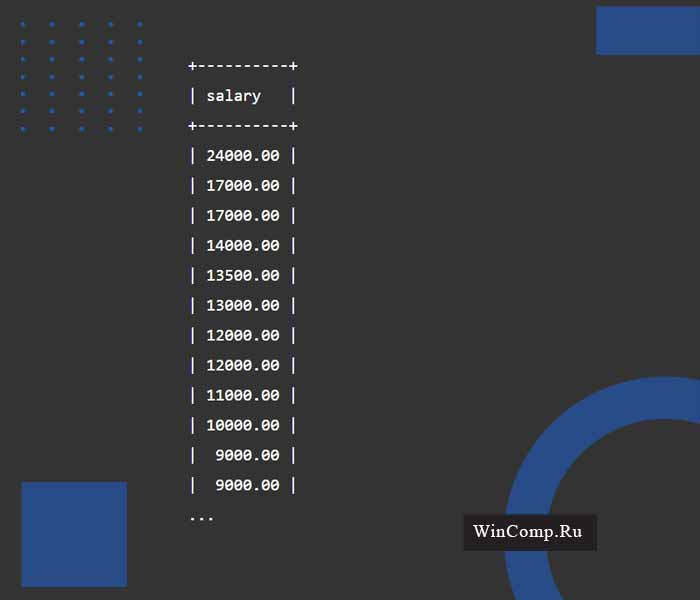
В наборе результатов есть несколько дублей. Например, 17000, 12000 и 9000.
В нижеследующем примере используется операнд SQL SELECT DISTINCT для того, чтобы выбрать уникальные записи из колонки зарплаты таблицы сотрудников:
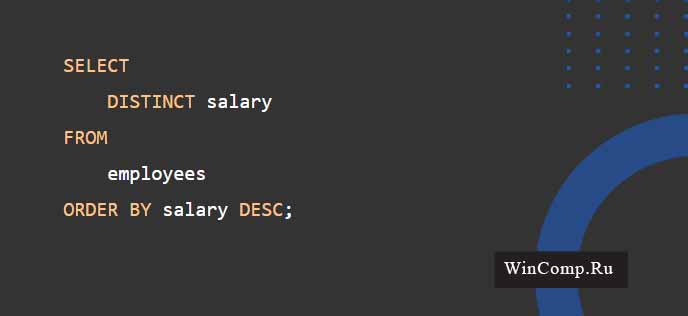

На скриншоте выше можно увидеть, что выборка данных не содержит дубликатов значений зарплаты.
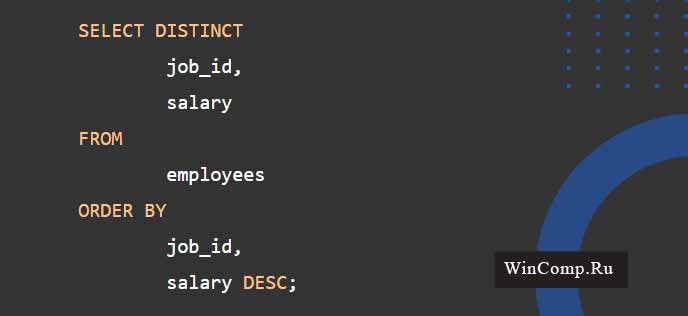
2) Использование оператора SQL DISTINCT на примере нескольких столбцов
Команда SELECT на скрине ниже производит отбор идентификатора должности (id) и зарплаты из таблицы employees:
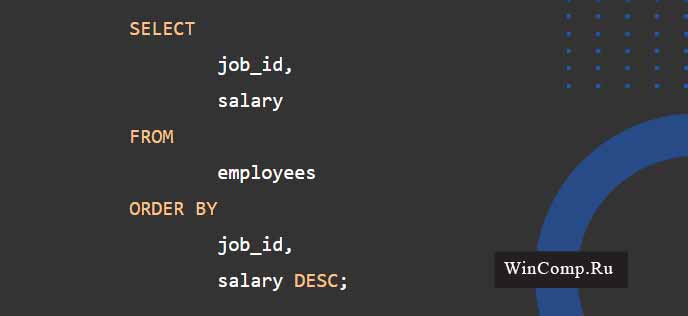

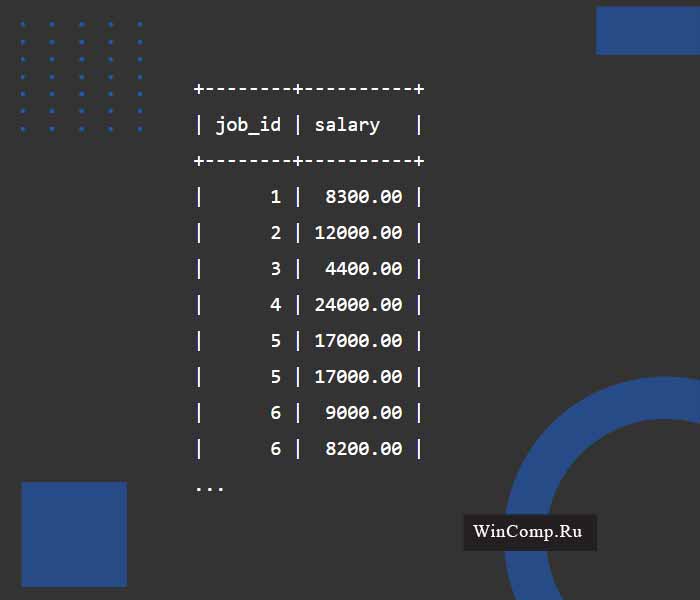
В итоге получаем несколько задублированных записей. К примеру, job_id=5 и salary=17000. Это говорит о наличии двух сотрудников с одними и теми же id должности и одинаковой зарплатой.
На примере ниже мы можем увидеть запрос к БД, где скрываются подобные дублирующиеся значения и остаются только уникальные записи по идентификатору должности и окладу:
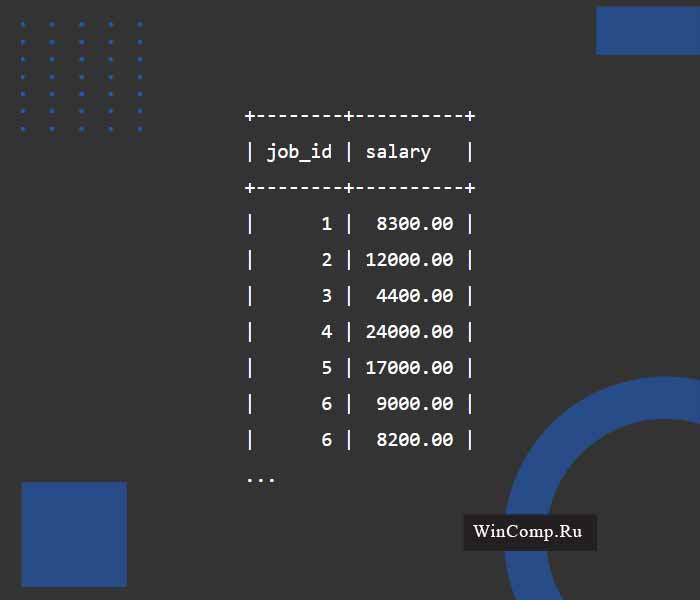
Обратите внимание, вы все еще можете наблюдать дубль в колонке job_id, что связано с тем, что предложение SELECT DISTINCT скрывает дубли которые имеют одинаковые парные значения job_id и salary для оценки, а не только данные из колонки job_id.
SQL DISTINCT и NULL
В базе данных NULL означает неизвестные или отсутствующие данные.
В отличие от таких значений, как числа, строки, даты и т. д. NULL не равен ничему, даже самому себе. Следующее выражение вернет неизвестные данные (или NULL):

Обычно оператор DISTINCT рассматривает все NULL одинаково. Поэтому оператор DISTINCT сохраняет только один NULL в наборе результатов.
Обратите внимание, что в разных продуктах баз данных это поведение может отличаться.
Например, следующий запрос возвращает разные номера телефонов сотрудников:
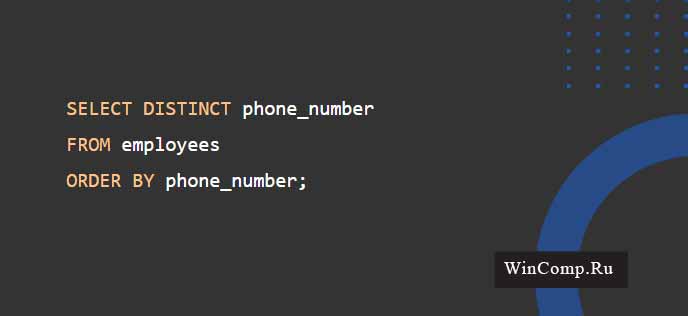

Следует заметить, что запрос возвращает только один NULL в наборе результатов.
Сводка
Используйте оператор DISTINCT в предложении SELECT для фильтрация данных и удаления дубликатов строк из набора результатов.
Предыдущая статья: Предложение ORDER BY
Следующая статья: Выражения LIMIT и OFFSET